-
Abstract
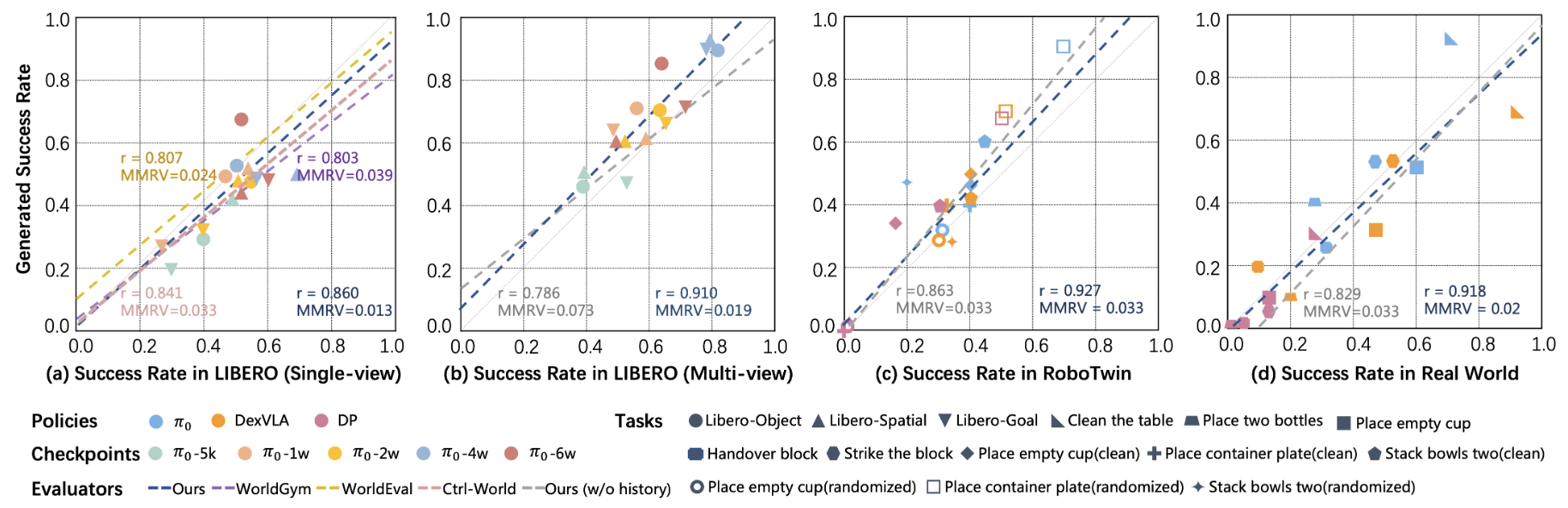
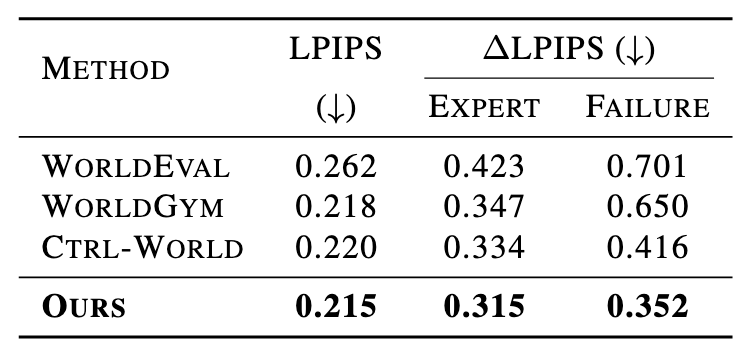
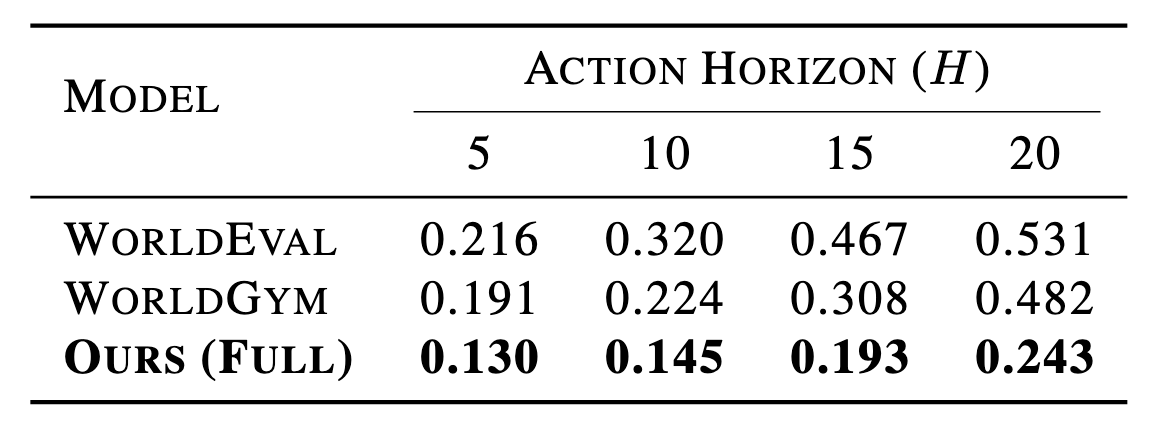
Evaluating generalist robot manipulation policies is costly and difficult to scale in the real world. While emerging world models (e.g., WorldEval, Ctrl-World) offer a promising alternative, the reliability of such evaluation remains a critical bottleneck. Specifically, their visual predictions can undermine policy assessment by "self-correcting" failures into false positives or yielding artifacts under out-of-distribution controls. Even with failure-enriched data, current architectures struggle to capture action-causal dynamics, as they typically treat actions as passive conditions rather than causal drivers. To address this, we propose dWorldEval, an action-centric discrete-diffusion world model that maps visual observations, language instructions, and action chunks into a shared unified token space and denoises them with a single self-attention backbone where actions function as first-class tokens. To realize reliable policy-world interaction, dWorldEval introduces a sparse keyframe memory that anchors global scene state while preserving fine-grained multi-view interaction cues, and leverages Progress-as-text to jointly generate future observations and success indicators. Extensive experiments on LIBERO, RoboTwin, and real-robot tasks demonstrate that dWorldEval significantly outperforms video diffusion baselines in action controllability, stabilizes long-horizon multi-view rollouts, enabling accurate policy ranking via automatic success estimation.
-
Overview
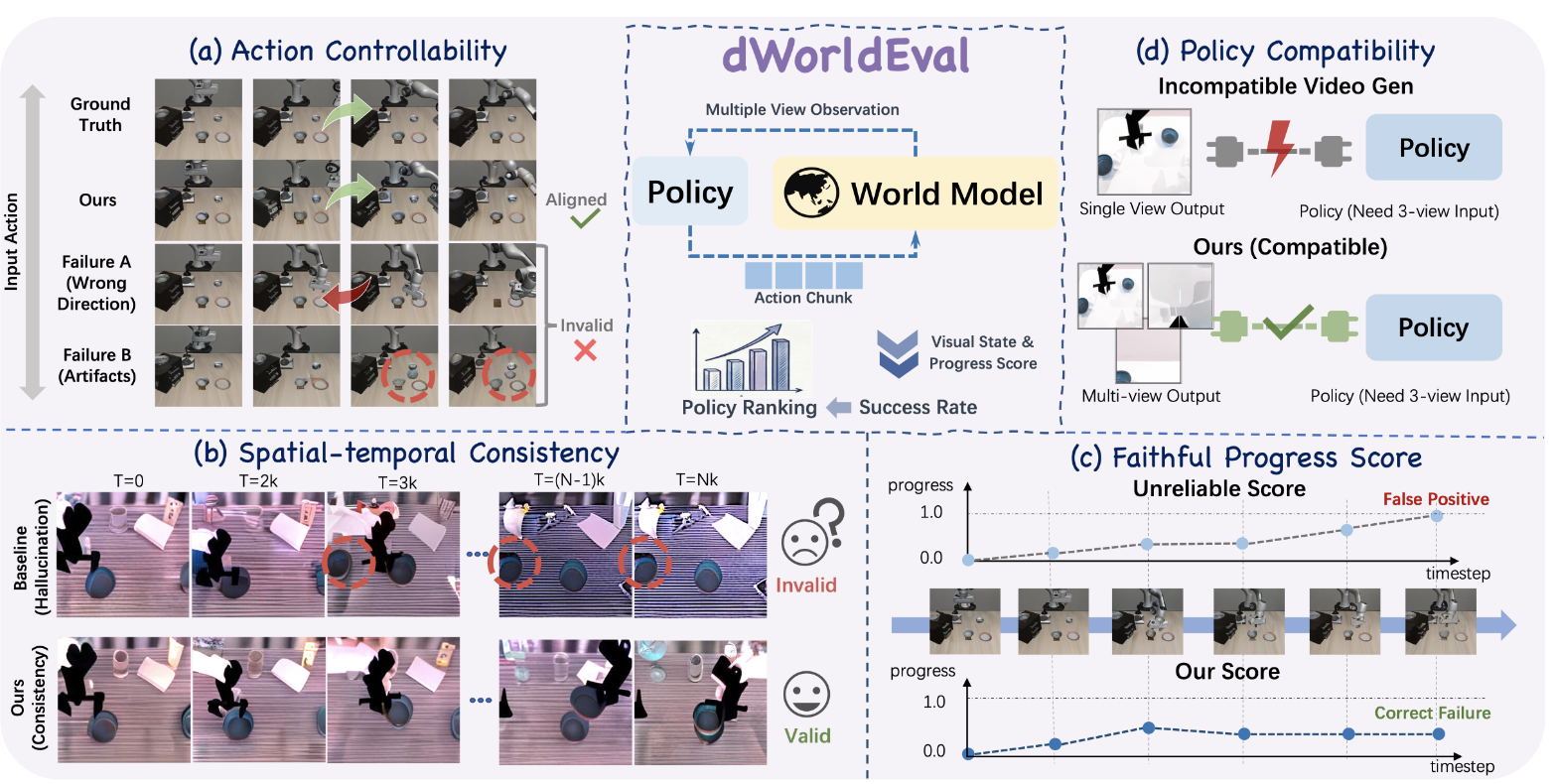
Architecture of dWorldEval